Place your votes: BNA Council & Committee elections
22nd July 2024


9th Feb 2022
Would you be able to find a café after just one previous visit? The answer for human and non-human animals is yes: they have the ability to return to a specific location after as little as one previous experience. This is referred to as one-shot learning. How does the nervous system achieve such a rapid and accurate task?
Published in the open access journal, Brain and Neuroscience Advances, researchers at the University of Nottingham used a reinforcement learning (RL) framework to study this phenomenon in ‘watermaze tasks’. Their article compared novel and existing RL-based approaches based on behavioural performance (could it reproduce rapid place learning?) and neurobiological realism (does it align with neurobiological findings?).
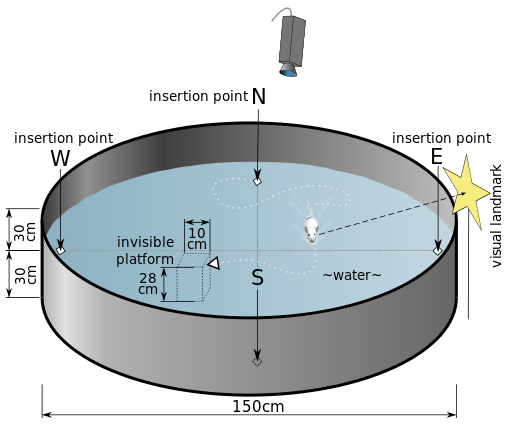
Watermaze tasks are a type of laboratory experimental design, where rats have to find a hidden platform in a pool of cloudy water surrounded by spatial cues.
The authors of the paper discussed a particular watermaze task in which the location of the platform remains constant during the four trials rodents are exposed to throughout the day, but is changed from one day to the next. At the start of a new day, the rats get much faster at finding the re-located platform between their first and second attempt (or trial). This is indicative of one-shot learning.
Replicating one-shot learning computationally has long been a challenge for RL researchers. A previous model by Foster et al. (2000) needed many trials to accurately navigate to the new goal, once the goal location had been changed. Could the Foster model be improved to better replicate one-shot learning?
Classical RL problems involve four components: states, actions, value functions and a policy.
In the case of the watermaze, states may be the locations of the agent, and actions are the decision to move from one location to another. The value function refers to the future expected reward from being in a state, and the policy represents a probability distribution of the agent’s possible actions. The policy determines which actions are most likely to be chosen at a given location and has to be learned to maximize the value function.
The authors of this paper used a different RL approach, employing an actor–critic learning architecture. Instead of following a fixed policy and appraising it based on the computation of the value function, the agent progressively updates their prediction of the environment using temporal difference (TD) learning.
In the watermaze the agent may compare their estimated location with their actual location; if there is a discrepancy between the two, the agent needs to update their predictive map of the maze.
What changes do the authors make to Foster’s model to improve replication?
The authors discuss a neurobiological implementation of Foster's (2000) coordinate-based navigation model in line with recent experimental findings about goal and vector-goal encoding in the brain. They also raise an interesting discussion on how extremely small or large spatial width represented by place cells would influence place learning. Place cells are neurons in the hippocampus that are more active when an animal is around a particular place.
Introducing a hierarchical approach, the authors also add another level of control to their model, which allows separating the predicted goal location with the control of the trajectory to reach it. They discuss whether this level may be equated to the involvement of prefrontal regions in rapid place learning.
Want to find more about one-shot learning and how this model is situated within other neurobiological findings? Click here to read the full article
References
Foster D, Morris R and Dayan P (2000) A model of hippocampally dependent navigation, using the temporal difference learning rule. Hippocampus 10(1): 1–16
About Brain and Neuroscience Advances
Brain and Neuroscience Advances is a peer-reviewed, open-access journal, which publishes high quality translational and clinical articles from all neuroscience disciplines; including molecular, cellular, systems, behavioural and cognitive investigations.
The journal welcomes submissions in basic, translational and/or clinical neuroscience. Research papers should present novel, empirical results that are expected to be of interest to a broad spectrum of neuroscientists working in the laboratory, field or clinic.
Brain and Neuroscience Advances is now indexed in PubMed Central.
Never miss the latest BNA news and opportunities: sign up for our newsletter




